Some notes about cortex architecture
Cortex, started by Tom Wilkie and Julius Volz (Prometheus’ co-founder) in 2016, has several interesting architectural features. As one of Prometheus’ long-term storage solutions, Cortex has been referenced by many time-series based storage architectures (tracing, log) since then (especially in the Grafana stack).
Prometheus⌗
Prometheus can be considered a kind of monolithic architecture.
Because everything is together, technical problems (that arise in microservices) do not occur, but each component cannot be scaled individually according to its specific purpose. In some ways, Cortex can be seen as a microservice version of Prometheus.
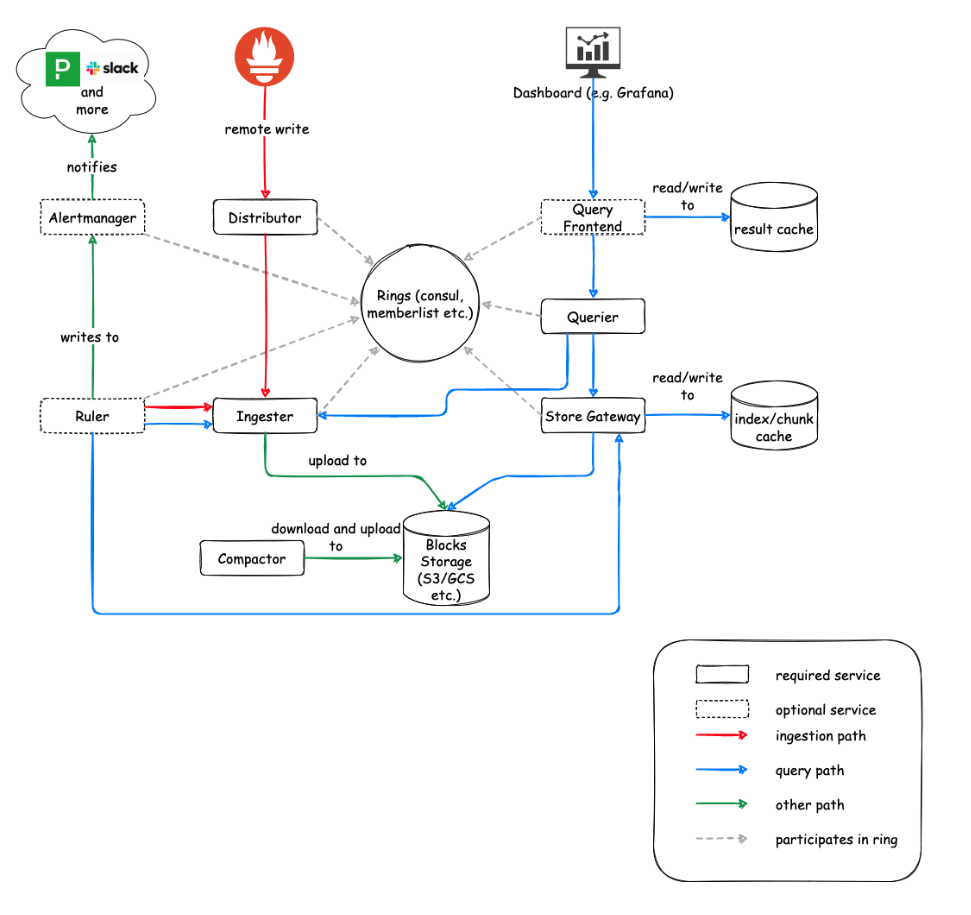
Ingester & Distributor⌗
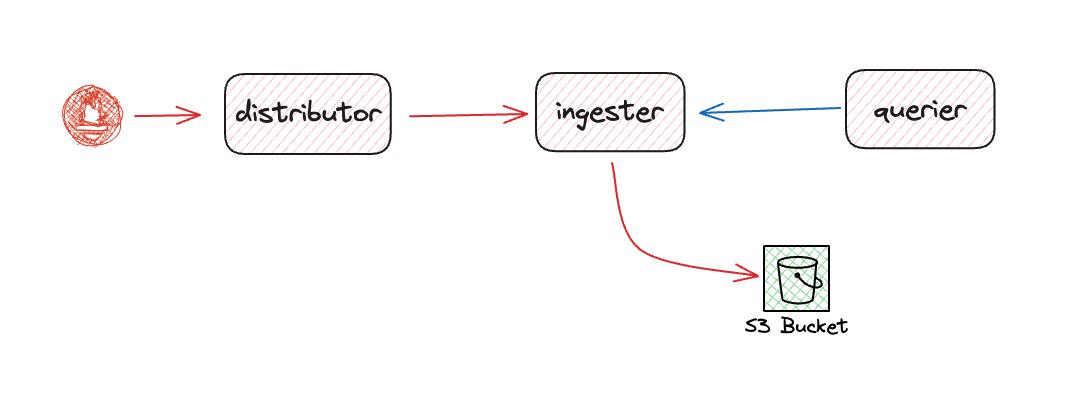
In Cortex, the ingester is the most important component. It’s the component that collects time series through Prometheus remote write, and since Prometheus TSDB creates blocks every 2 hours, it needs to respond to querier’s query requests for metrics from the last 2 hours. Since it holds the TSDB’s Head Block in memory, it’s fast for recent metric requests. Due to the nature of time series usage, recent data usage is an important pattern (e.g., for alerts).
Data replication is important for reliability in any distributed system design. The Distributor also copies the same data to multiple Ingesters according to the RF (Replication Factor). It might seem like a waste of resources, but if a specific ingester fails, another ingester with replicated data can respond. From a query performance perspective, queries can be distributed based on duplicated data.
Ingesters don’t need to know much about each other. This advantage creates another disadvantage: duplicated data is uploaded to S3. Later, the compactor cleans up this duplicated data (similar to LSM Tree).
What happens if an ingester restarts before uploading a block (before 2 hours)? The ingester must upload the data it has so far to S3 during shutdown.
Store gateway & Compactor⌗
Looking at the TSDB structure, a database called a block is created hourly, and data is stored as index and chunks within the block. The ingester stores these TSDB blocks in an object store (S3), and the store gateway finds and delivers the necessary TSDB in response to querier requests. Since the store gateway needs to retrieve large amounts of data from the slow object store, it uses caches for the index and chunks, and query performance depends heavily on the cache hit ratio.
The compactor takes blocks that start at 2 hours and gradually creates larger blocks with increased time spans. Since there are duplicate indexes across different time periods, compaction also has a (positive) impact on query performance.
Some notes about Cortex architecture⌗
In my personal opinion, Cortex architecture seems like a kind of distributed and coordination-(half)free architecture. If you look at RDB sharding solutions, they have a lot of meta information needed for coordination between each component, but Cortex only maintains simple status and connection information for ingesters in metastores like Consul. They don’t hold much information about each other and allow duplicated data and fan out requests redundantly, but because they don’t know much about each other, they can act simply.